
Using Neo4j with Seneca: Part I
Introduction
In my previous post I introduced the Seneca microservices framework and explained why I’m using it. I mentioned that I have contributed a Neo4j graph database store plugin to this framework and promised I’d give you an example of how to use it with the user plugin. I’m now going to break that promise (naughty blogger!!). Before I give an example of how to use it I want to explain how it came about. I’ll explain how to use it in my next post (honest).
Background
The seneca-neo4j-store plugin works like any other Seneca store plugin. It allows us to persist data entities without the need to know anything about how or where it is done. This is a problem, however - if we use it as a simple replacement for, say, the MySQL plugin then all we’ve done is to exchange nodes in the graph database for rows in a SQL database. We’re not using the power of the graph in any way, so why bother?
Why bother with Neo4j?
Graph databases offer a number of advantages over relational databases due to the nature of the data they describe. Whereas relational databases represent entities as rows in a table, graph databases represent entities as nodes (sometimes called vertices). In addition to this they define relationships (or edges) between nodes. Both nodes and relationships can have properties (key-value pairs). Nodes can be labelled with one or more labels.
Relationships are named and directed and always have a start and end node. The beauty of the graph is that the relationships between nodes are built into the graph itself (i.e. there is no need for expensive join tables). Once you’ve found the start node you can traverse a small, related sub-set of the overall graph to find the results you need which leads to blisteringly fast performance. There are other advantages, but let’s limit ourselves to this for now.
What do we do about it?
My point is that using a graph database in the same way as a relational database is like owning a Ferrari and driving it everywhere in reverse. To a certain extent, introducing a graph database plugin to Seneca is anathema. The beauty of Seneca data stores is that they provide the simplest model for data in the form of basic Create-Read-Update-Delete data operations. These map onto a set of conventional message patterns of the form of role:entity, cmd:save|load|remove|list. The trade-off to this is that these messages represent the lowest common denominator. It enables what is essentially a key-value store with reasonable, if limited, query capabilities. Data must be normalised because you don’t get table joins.
This is clearly an issue with respect to graph databases. Using a graph database without relationships makes no sense. A consequence of this is that the seneca-neo4j-store introduces two new messages, saveRelationship and updateRelationship which don’t conform to the standard Seneca data store metaphor. It is interesting to note that Seneca will be expanding the basic data store but for now we have broken extended the pattern.
Dealing with Nodes (or Vertices)
Creating nodes (otherwise known as vertices) in this store is exactly the same as creating an entity in other Seneca data stores; the entity name defines the label of the node being saved/updated and it’s fields become the properties of that node.
When it comes to creating relationships, things get tricky. It becomes necessary to identify both the origin and destination nodes as well as defining the relationship between them. Accommodating three different sets of fields representing three different but related data structures cannot be done using the existing metaphor, in my humble opinion, without stretching that metaphor beyond breaking point. You may think that extending the basic store methods also extends the store metaphor beyond breaking point - if so I’d welcome your suggestions for ways of doing it differently.
Given that using a database that relies on relationships between entities is breaking the store metaphor anyway I didn’t see much harm in stretching it a little further. If it’s any consolation, this new metaphor can be used interchangeably with any graph database (such as the OrientDB store plugin I’m currently creating).
Dealing with Relationships (or Edges)
The existing store messages save|load|list|remove can be used the same way as for any other store to operate on nodes. The methods for relationships work a little differently. Consider the following simple graph:
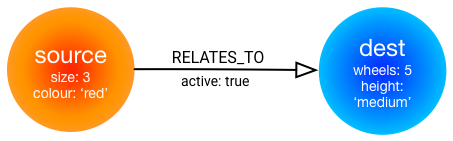
This can be expressed in Cypher (Neo4j’s query language) as:
CREATE (s:source { size:3, colour:'red'})-[r:RELATES_TO {active:true}]->(d:dest { wheels:5,height:'medium'}) RETURN s,r,dFirst, let’s create the source and destination nodes:
var s = seneca.make$('source')
s.size = 3
// sorry, I'm English so I spell color correctly!
s.colour = 'red'
s.save$(function (err, entity) { ... })
var d = seneca.make$('dest')
d.wheels = 5
d.height = 'medium'
d.save$(function (err, entity) { ... })Now we’re ready to create a relationship between them:
// establish the source node (or nodes)
var s = seneca.make$('source')
s.size = 3
// describe the relationship between them
var rel = {
relatedNodeLabel: 'dest', // required: identifies the label of the destination node
type: 'RELATES_TO', // required: defines the relationship type
data: { // optional: used to add properties to relationships
active: true
// we can use sort$, limit$, skip$ and fields$ here when retrieving
// related nodes and they will apply to the relationship only
}
}
// identify the properties of the desired destination node:
var dest = {
colour: 'red'
// we can use sort$, limit$, skip$ and fields$ here when retrieving
// related nodes they will apply to the destination node only. If limit$
// and skip$ are used both here and in the relationship the
// relationship values will be applied in preference to the
// destination node values.
}
// now we can incorporate the relationship data in the destination...
dest.relationship$ = rel
// ...and save the relationship:
source.saveRelationship$(dest)To avoid ambiguity, I have assumed that the source and destination entities already exist before the relationship is created (even though Cypher will allow us to create the source, destination and relationship in the same statement). This has the advantage that we can use a single saveRelationship invocation to create one or many relationships. How many relationships are created depends upon how many source and destination nodes exist and what field values you use to identify them.
The relationship$ field can be used in load$, list$ and remove$ method calls. In the case of retrieval, the relationship$ value will be used to return destination nodes that match the relationship definition (the entity on which the methods are invoked will be the source node). In the case of deletion it is the relationship itself that will be deleted, not the source or destination nodes. Relationships can be updated by calling updateRelationship$. Any properties supplied in the relationship data object will be updated. Properties that are not included in the data object will remain the same. Relationship properties can be removed by including them in the data object and setting their value to null.
Native Driver
As with all seneca stores, you can access the native driver.
entity.native$(function(err, dbInst){ cypher: ..., params: ..., name$: ...})
The native driver takes 3 parameters:
cypher- required: The native cypher query statementparams- optional: The parameters associated with the cypher queryname$- optional: The entity name to be associated with the returned results, as in$-/-/<name>;...If not supplied, the entity name will default to ‘entity’, as in$-/-/entity;...
With the dbInst object you can perform any query using Cypher.
entity.native$(function(err, dbInst){
dbInst.query({ cypher: 'MATCH (n) RETURN n LIMIT 25' }, function (err,results){
if(!err){
return results;
}
});
})Configuration
The seneca-neo4j-store plugin requires a configuration object to be passed to it, as shown below:
var seneca = require('seneca')()
seneca.use('neo4j-store', {
'conn': {
'url': 'http://localhost:7474/db/data/transaction/commit',
'auth': {
'user': 'neo4j',
'pass': 'neo4j'
},
'headers': {
'accept': 'application/json; charset=UTF-8',
'content-type': 'application/json',
'x-stream': true
},
'strictSSL': true
},
'map': { '-/-/-': ['save', 'load', 'list', 'remove', 'native', 'saveRelationship', 'updateRelationship'] },
'merge': false }) This object is typically defined in a configuration file and require‘d at the point of use. Since Seneca is written in Node.js we won’t be embedding Neo4j but will be running a Neo4j server and connecting to it. Note that we need to define the map object to include our new methods otherwise they won’t be visible to the code using the store.
Conclusion
Now that I’ve explained how my seneca-neo4j-store plugin works I can fulfil my promise from the previous post of giving an example of how to use this plugin with the user plugin to get the most from graphs… in my next post!




Leave a comment